Windows10 + AnacondaでMediaPipe動かしてみた
はじめに
こちらQiitaに公開した記事のバックアップです
ほとんど手を付けられてなかったMediaPipeでしたが、やる気が少し湧いたのでWindows10で動かしてみました。
この記事はWindows10とAnacondaでMediaPipeを動かしたときの備忘録となっております。
MediaPipe自体についてはこちらから確認いただけるとよいと思います。
公式では15個のソリューションがサンプルとして公開されており、今回はPythonに対応している以下6個のソリューションを実装して試してみました。
(本記事とほぼ同じ内容をGithubにあげておりますので、試してみたい方はこちらからどうぞ)
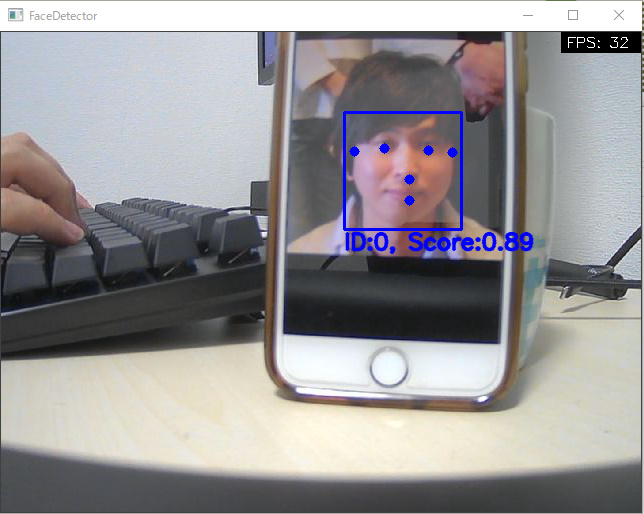
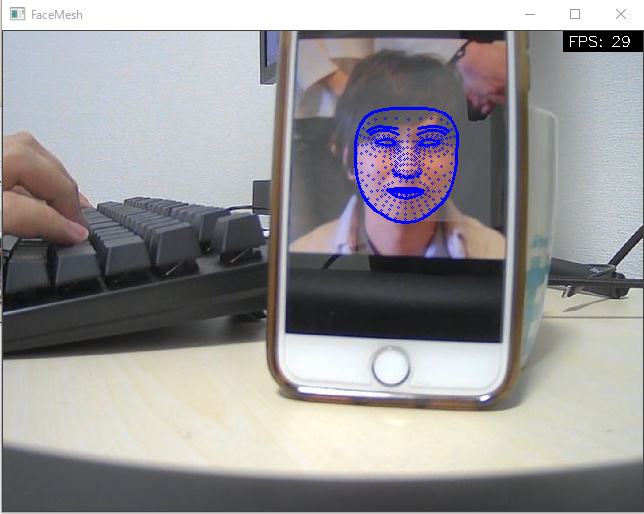
| Face Detection | Face Mesh |
|---|---|
 |
 |
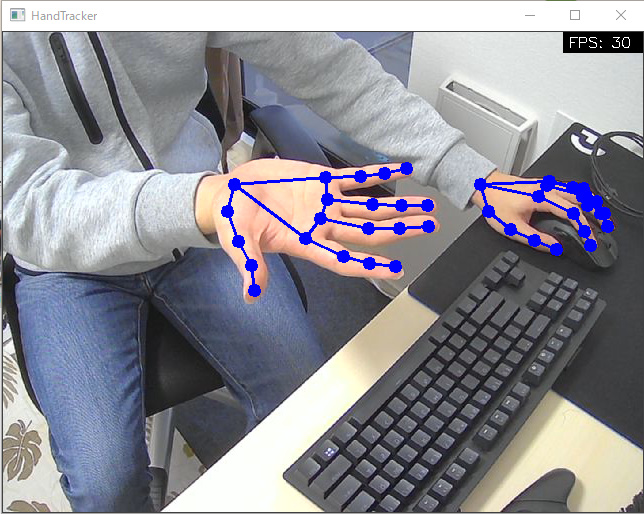
| Hands | Pose |
 |
 |
| Holistic | Objectron |
 |
 |
開発環境
タイトルにもあるようにWindows10上で開発を行いました。
- Windows 10 home Insider Preview 10.0.21327 build 221327
- Core(TM) i7-9700K CPU @ 3.60GHz
- Anaconda 4.8.2
- Web Camera
環境構築
Anacondaで仮想環境を構築し、その中にMediaPipeをインストールして開発します。
注意)あまりよくないのですがcondaとpipを使ってインストールしています。現状は特に問題は出ていませんが、実施する場合は自己責任でお願いいたします。
(base) $ git clone https://github.com/T-Sumida/mediapipe_python4windows.git (base) $ conda create -n mediapipe python=3.7 (base) $ conda activate mediapipe (mediapipe) $ conda install requests (mediapipe) $ pip install mediapipe, loguru
実装
この記事ではHandsについてのみ記載します。(以下をコピーしただけでは動きませんので、こちらをご確認ください。)
大まかに、「Main」と「FPS計算」「ML」部分に分けて実装しています。
Main部分
main部分では、引数機能とカメラ制御、描画を担当するようにしています。
また、Face Detection以外も扱えるように、argparseのsubpasersを使ってサブコマンドでソリューションを指定できるように作っています。 そのサブコマンド名自体をML部分のクラス名と同一にしておいて、getattr関数でML処理のインスタンスを作成するような形としています。
# -*- coding:utf-8 -*- import copy import argparse import cv2 import numpy as np from loguru import logger import models from utils import FpsCalculator def get_args() -> argparse.Namespace: """引数取得 Returns: argparse.Namespace: 取得結果 """ parser = argparse.ArgumentParser() parser.add_argument("--device", help='device id', type=int, default=0) parser.add_argument("--width", help='capture width', type=int, default=960) parser.add_argument( "--height", help='capture height', type=int, default=540 ) subparsers = parser.add_subparsers(dest="model") # hand_tracker command parser parser_ht = subparsers.add_parser( 'HandTracker', help='', description='HandTracker' ) parser_ht.add_argument( '--max_num_hands', type=int, default=2, help='最大検出手数' ) parser_ht.add_argument( '--min_detection_confidence', type=float, default=0.7, help='手検出モデルの最小信頼値 [0.0, 1.0]' ) parser_ht.add_argument( '--min_tracking_confidence', type=float, default=0.5, help='ランドマーク追跡モデルの最小信頼値 [0.0, 1.0]' ) args = parser.parse_args() return args def draw_fps(image: np.ndarray, fps: int) -> np.ndarray: """fpsを描画する Args: image (np.ndarray): ベースイメージ fps (int): FPS Returns: np.ndarray: 描画済みイメージ """ width = image.shape[1] cv2.rectangle(image, (width-80, 0), (width, 20), (0, 0, 0), -1) cv2.putText(image, "FPS: " + str(fps), (width-75, 15), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255), 1) return image def main() -> None: """メインループ""" args = get_args().__dict__ # setting camera device cap = cv2.VideoCapture(args['device']) cap.set(cv2.CAP_PROP_FRAME_WIDTH, args['width']) cap.set(cv2.CAP_PROP_FRAME_HEIGHT, args['height']) del args['device'], args['width'], args['height'] # setting detector try: model_name = args['model'] del args['model'] detector = getattr(models, model_name)(**args) except Exception as e: logger.error(e) exit(1) # setting fps calculator calculator = FpsCalculator() # main loop while cap.isOpened(): ret, image = cap.read() if not ret: break image = cv2.flip(image, 1) tmp_image = copy.deepcopy(image) image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) if detector.detect(image): tmp_image = detector.draw(tmp_image) fps = calculator.calc() tmp_image = draw_fps(tmp_image, fps) cv2.imshow(model_name, tmp_image) if cv2.waitKey(1) & 0xFF == ord('q'): break return if __name__ == "__main__": main()
FPS計算部分
この処理に関しては、以下ページを参考にさせていただきました。(ありがとうございます!)
# -*- coding:utf-8 -*- from timeit import default_timer as timer class FpsCalculator(): def __init__(self) -> None: """Initial""" self.frame_count = 0 self.accum_time = 0 self.curr_fps = 0 self.prev_time = timer() self.result_fps = 0 def calc(self) -> int: """calc fps Returns: int: current fps """ # update frame count self.frame_count += 1 # update fps self.__curr_time = timer() self.__exec_time = self.__curr_time - self.prev_time self.prev_time = self.__curr_time self.accum_time = self.accum_time + self.__exec_time self.curr_fps = self.curr_fps + 1 if self.accum_time > 1: self.accum_time = self.accum_time - 1 self.result_fps = self.curr_fps self.curr_fps = 0 return self.result_fps
ML部分
以下のようなクラス設計にし、他のソリューションを追加した場合も簡単に拡張できるようにしております。
Python版MediaPipeの扱い方に関しては以下を参考にしております。
https://google.github.io/mediapipe/solutions/face_detection.html
かなり簡単に実装ができて、モデルロード・推論・結果取得がすごく簡単でした。(コメントで★を入れている箇所)
結果取得に関しては、試すソリューションによって少し異なりますが公式に分かりやすく載っているので、非常に良かったです!
# -*- coding:utf-8 import cv2 import numpy as np import mediapipe as mp from loguru import logger from .abst_detector import AbstDetector class HandTracker(AbstDetector): def __init__(self, max_num_hands: int, min_detection_confidence: float, min_tracking_confidence: float) -> None: """初期化処理 Args: max_num_hands (int): 最大検出手数 min_detection_confidence (float): 手検出モデルの最小信頼値 min_tracking_confidence (float): ランドマーク追跡モデルからの最小信頼値 """ # モデルロード★ self.tracker = mp.solutions.hands.Hands( max_num_hands=max_num_hands, min_detection_confidence=min_detection_confidence, min_tracking_confidence=min_tracking_confidence, ) def detect(self, image: np.ndarray) -> bool: """手検出処理 Args: image (np.ndarray): 入力イメージ Returns: bool: 手が検出できたか """ try: # 推論処理★ self.results = self.tracker.process(image) except Exception as e: logger.error(e) return True if self.results.multi_hand_landmarks is not None else False def draw(self, image: np.ndarray) -> np.ndarray: """処理結果を描画する Args: image (np.ndarray): ベースイメージ Returns: np.ndarray: 描画済みイメージ """ base_width, base_height = image.shape[1], image.shape[0] for hand_landmarks, handedness in zip(self.results.multi_hand_landmarks, self.results.multi_handedness): landmark_buf = [] # 結果取得★ # keypoint for landmark in hand_landmarks.landmark: x = min(int(landmark.x * base_width), base_width - 1) y = min(int(landmark.y * base_height), base_height - 1) landmark_buf.append((x, y)) cv2.circle(image, (x, y), 3, (255, 0, 0), 5) # connection line for con_pair in mp.solutions.hands.HAND_CONNECTIONS: cv2.line(image, landmark_buf[con_pair[0].value], landmark_buf[con_pair[1].value], (255, 0, 0), 2) return image
デモ
実際にHandsを使ったデモを動画として残しております。
おわりに
今回はMediaPipe公式が提供しているPython版ソリューションをWindows+Anacondaで試してみました。
本当はWSL2上で動かしてみたかったのですが、私の環境ではまだWebカメラは認識してくれなかったため断念しました...
今後は提供されたソリューションで遊ぶのではなく、自分でMLパイプラインを構築して試してみたいと考えております。